
异常检测(Anomaly Detection)之一类支持向量机(One-Class SVM)・孤立森林(Isolation Forest)
前言
世事难料,没想到工作使我转行做起了大数据,而我之前并未接触过相关内容,想必会有一个相对长久的学习期,因此计划写点什么类似于学习记录的东西—都是些基础,且考虑到我的学习路径会由工作内容驱动,因此也并非什么都会写,算是拍拍脑袋的产物吧。
1.异常检测
我的任务是尝试去一坨数据中分辨出可能存在异常的部分,比方说我拿到了某个测温仪工作数据,我希望通过这些数据来了解该测温仪是否存在异常。 但遗憾的是,没有人能告诉我究竟什么样的数据是异常数据。 因此,我只好假设,异常情况在总的数据样本中占极少数且与众不同—这也符合常理以及异常的定义。 于是接下来的工作便是想些方法对数据进行一个分类,将这些可能的少数派给分离出来。
在前辈的指点下,我学习并尝试了两种方法,也就是标题中所提到的一类支持向量机和孤立森林。 它们本质上都是在测算每个样本到标定点的某种距离,考虑到正常的数据可能不会差的太多,因此他们到标定点的距离也不会差的太多,而那些与众不同的异常点一般来说是离群的,这也意味着其相对于标定点的距离可能会和正常的数据有明显的差距,于此便使得通过距离来识别异常变的可能。
这两种方法以机器学习的语言来说叫做无监督学习(Unsupervised Learning),即没有给定事先标记过的训练用例,而自动的对数据进行分类。当然,如果异常数据并不符合上述少数且与众不同的假设,那么这种基于距离的分类方法的准确性就无从保证。 所以更多时候,这类算法的结果只是用来提供一种思路,为之后更进一步的算法做准备。
2.一类支持向量机
说到分类,支持向量机(Support Vector Machine)可以说是最为常见的方法之一了,即便是我这个对于机器学习只有道听途说级别的人,或多或少也在各种地方甚至于梗图中看见过这个名词。 对于已经标记好的两类数据样本,倘若你将这些样本数据想象成空间中散布的不同颜色的点的话,支持向量机的想法便是寻找一个平面,将这不同颜色的点分隔开来。 也就是说,对于数据样本向量$\vec{x}$,我们通过如下函数来决定其属于何种类别。
\[y = \vec{w} \vec{x} - b\]其中向量$\vec{w}$与常数$b$经由支持向量机通过某种方式训练得到,而计算出的$y$值的正负将决定样本$\vec{x}$的类别。 而$y=0$时所确定的便是我们之前所提到的,分割不同类别的,(超)平面(Hyperplane)。
而我们的问题在于,数据并非是被标记的,因此传统的支持向量机并不能直接应用在我们所面临的问题上。 于是一个叫做Schölkopf的人提出,我们可以试着先寻找一个平面,使得所有的样本都在其一侧,且距离远点最远,如下图所示。
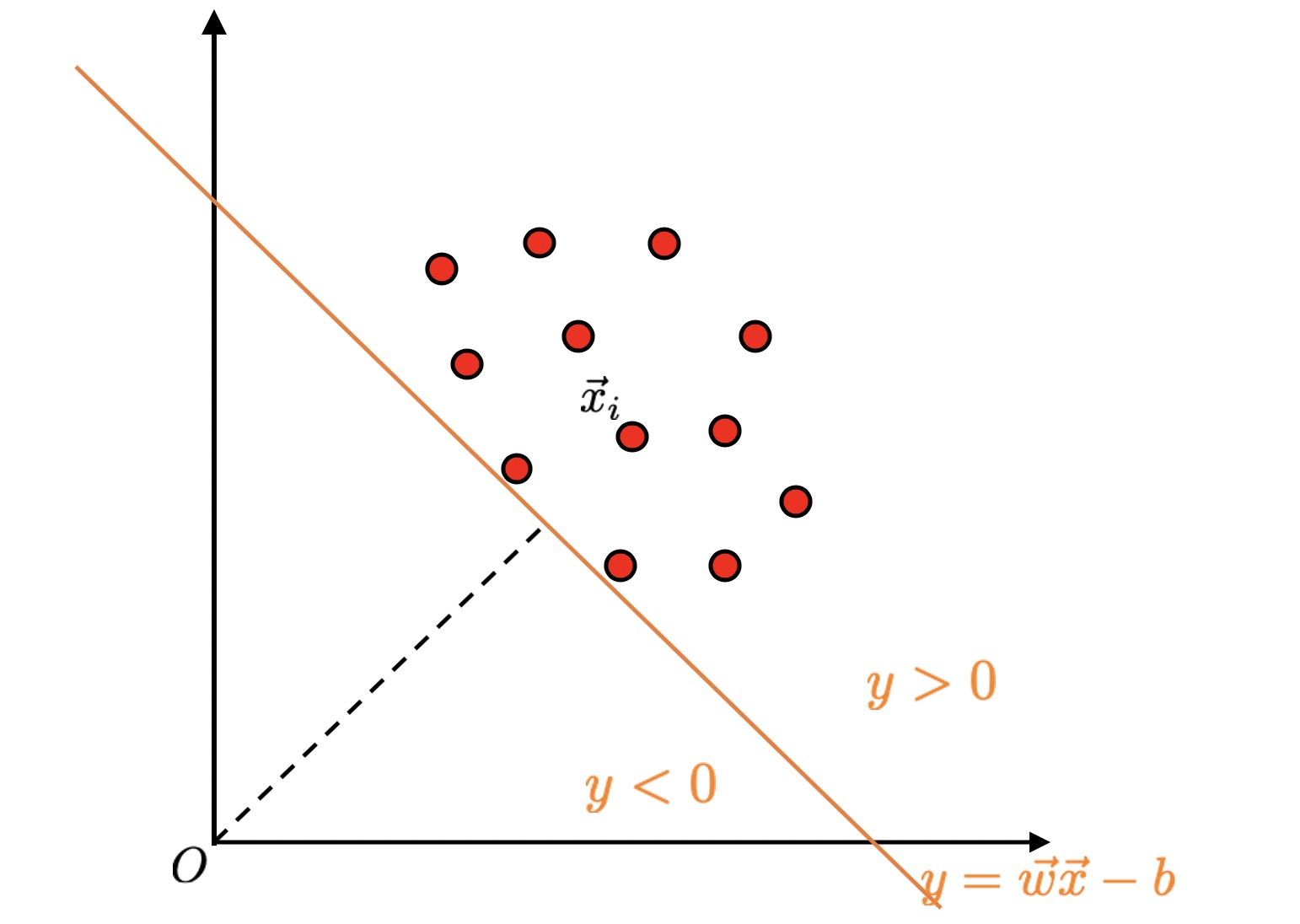
考虑二维空间的话,我们的目标便是寻找这条橙色的分界线,且使得原点到其的距离(黑色虚线)最小。
如何通过已有信息表达出这个距离呢?考虑到向量$\vec{w}$实际上与我们寻找的平面正交,因此任意的从原点出发,且与平面正交的向量$\vec{p}$,其长度$d(\vec{p})$为
\[\begin{align} \vec{p} &= d(\vec{p}) \frac{\vec{w}}{\left\|\vec{w}\right\|_2} \\ d(\vec{p}) &= \frac{\vec{w} \vec{p}}{\left\|\vec{w}\right\|_2} \end{align}\]当$\vec{p}$落在我们所寻找的平面上时,其满足$\vec{w}\vec{p} - b = 0$,因而原点到平面上的距离$r$为
\[r = \frac{b}{\left\|\vec{w}\right\|_2}\]于是我们的问题转变为如下最小化问题
\[\text{Minimize: } \frac{b}{\left\|\vec{w}\right\|_2}\]使得对于所有的数据样本$\vec{x}_i$满足
\[\vec{w}\vec{x}_i - b >= 0\]注意到最小化$\frac{b}{\left|\vec{w}\right|_2}$实际上就是要使得$\left|\vec{w}\right|_2 - b$最小, 于是目标函数可以改写为一种我们更加熟悉的凸优化问题的形式
\[\text{Minimize: } \frac{1}{2} \left\|\vec{w}\right\|^2_2 - b\]考虑到凸优化问题的局部最优即为全局最优,改写目标函数带来的优点不言而喻。
不过到目前为止,我们还并没有进入到我们真正想要解决的问题—筛选异常值。 如果数据中存在一些如下所示的异常值
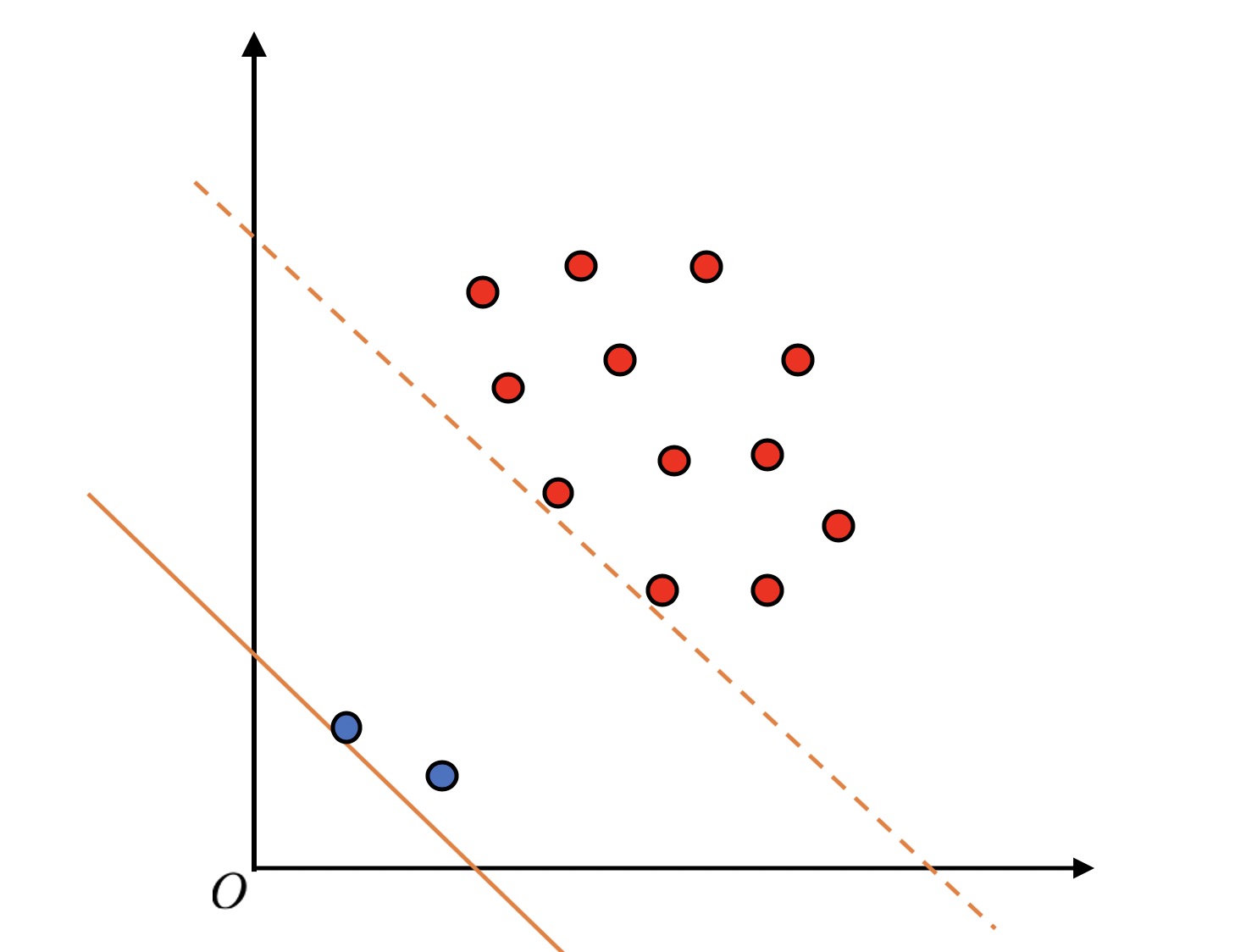
很显然我们希望得到图中虚线所示的平面,但受到异常值的影响,我们实际上会获得实线所示的平面。 因此,在计算平面时,我们要能够容忍一些点能够出现在平面与原点之间。
于是对于每个样本$\vec{x}_i$,我们引入变量$\xi_i$作为其容忍度—即便$\vec{x}_i$越过了平面,但只要距离没有超过$\xi_i$,就没有问题。 我们希望$\xi_i$能够尽可能的小,进而目标函数变为
\[\text{Minimize: } \frac{1}{2} \left\|\vec{w}\right\|^2_2 - b + \frac{1}{\nu n} \sum_i^n \xi_i\]其中$n$为样本总量,而$\nu$为我们认为的异常数据可能的占比,也即预期的会落入求得平面与原点之间的样本数占比,是一个人定参数。 注意到当$\nu$趋近于$0$时,目标函数中的第二项则趋近于无穷大—优化该项也就变得毫无意义,此时问题退化为之前未加入$\xi_i$的问题,符合我们的预期。 此时约束条件为
\[\begin{align} \vec{w} \vec{x}_i - b \ge -\xi_i, \forall i \in [1, n] \\ \xi_i \ge 0, \forall i \in [1, n] \end{align}\]这便是一类支持向量机的基本想法,于特征空间中寻找一个能够将数据样本与原点用最大间隔分开的超平面,外加一点点容忍值。 不过通常我们不会选择直接求解这个优化问题,而是通过拉格朗日乘数(Lagrange multiplier)将其转变为如下形式后进行求解
\[\text{Minimize: } \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_j \vec{x}_i \vec{x}_j\]使得
\[\begin{align} 0 \le \alpha_i \le \frac{1}{\nu n}, \forall i \in [1, n] \\ \sum_{i=1}^n \alpha_i = 1 \end{align}\]再说下去就都是些无聊的,我还没来得及学习的内容了,因此目前姑且先采取如下策略吧
from sklearn.svm import OneClassSVM现实中我们更多时候可能需要寻找的是曲面(线)而不是平面(直线),因此对于现实数据而言,上述想法通常不能直接适用。 不过幸运的是,通过一种叫做核方法(Kernel Method)的技巧,我们能够通过将数据样本映射到更高维度的方式,将非线性的分类问题转变为线性的分类问题,如下所示
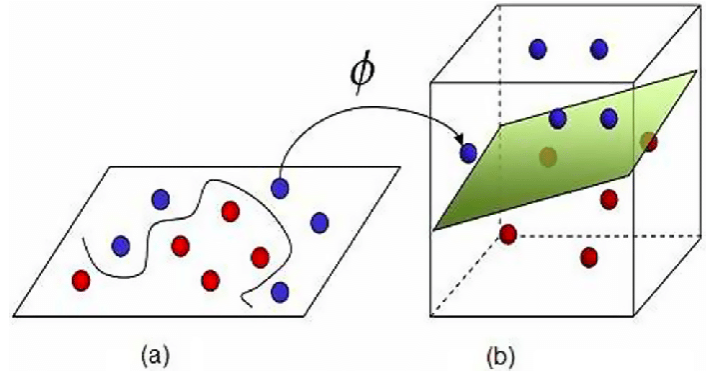
图中的映射$\phi$,我们一般称之为核函数(Kernel Function),待之后学习到了这部内容,便回来填上这坑—假设我没有忘记这事的话。
3.孤立森林
孤立森林的背后想法就更加的简单了—根据假设,异常数据占比显著较少,那么我随机从数据中抓取一个,其为异常值的概率也是相当低的。 当然,随机抓取还是太过分了,只是个玩笑话,并且也没有考虑到异常数据的异常特性,因此我们每次选取一个数据样本的特征$\mathcal{a}$,那么对于$n$个数据样本,我们将拥有$n$个$\mathcal{a}$特征的特征值。 之后,从这$n$个值之中随机选取一个作为轴(pivot),就像在快速排序中所作的那样,我们根据该轴将数据样本分割为大于轴与小于轴的两部分,并继续选取其他的特征,对这两部分重复该操作,直至样本数为1。
这个分割过程可以用一棵二叉树$T$来进行描述,二叉树$T$的叶子节点为某个数据样本,而根节点到该叶子节点的路径长度,便是分割次数。
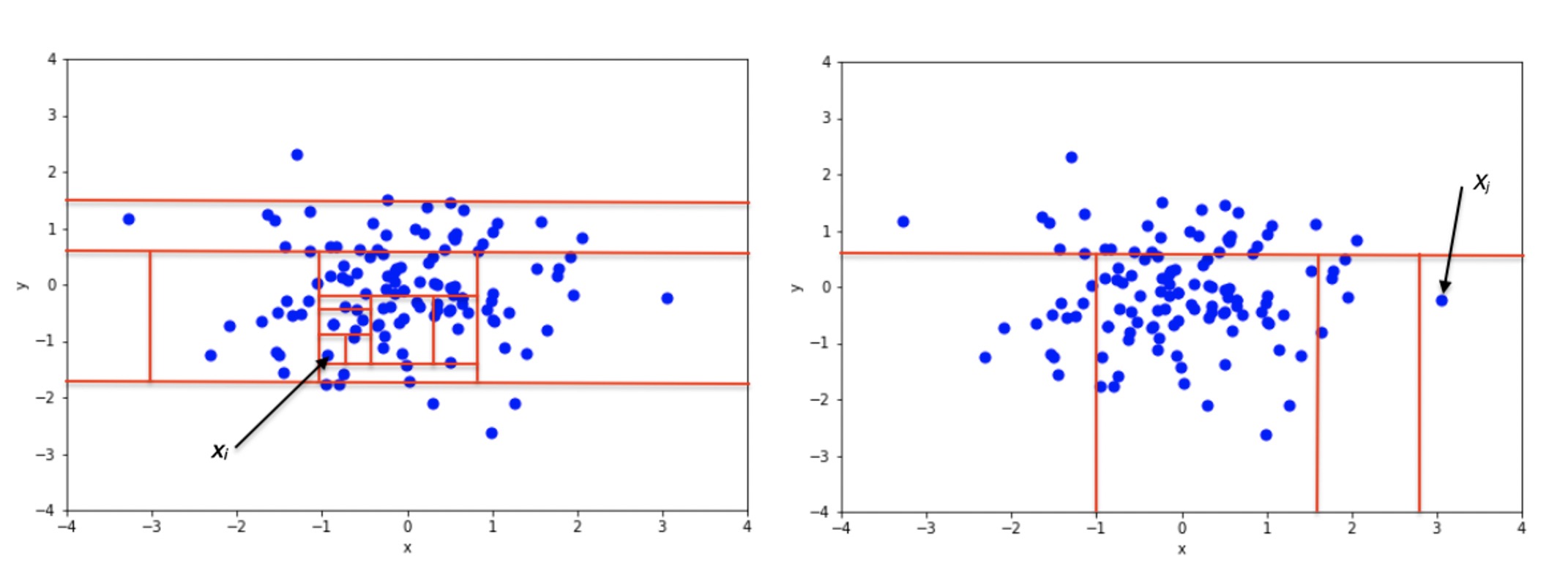
对于异常数据而言(图右),由于其偏离大部队,通过较少次数的分割,我们通常就能够找到它。 因此,对于某个数据样本$x_i$来说,以$T(x_i)$表示树$T$上与其相对于的叶子节点,我们便可以通过$T(x_i)$到根节点的路径长度来衡量其异常程度—越小越异常。
如何去做呢?实际上我们这棵二叉树$T$从某种意义上来说也是一棵二叉查找树(Binary Search Tree),对于每一个节点,其左右分别为小于和大于它的部分,符合二叉查找树的定义。 这提示我们,或许可以从二叉查找树的平均深度出发去定义一个衡量的方式。
对于一棵随机构建的二叉查找树,其平均深度是多少呢?我们从二叉查找树的查询操作出发去进行考量。 令$S(n)$与$U(n)$分别为在一棵随机构建的拥有$n$个节点的二叉查找树中成功查询与失败查询所需要比较的平均次数。 考虑到在成功查询到待查节点之前,我们相当于进行了一次完整的失败查询之后更进一步找到了待查节点,因此有
\[\begin{align} S(n) &= ((U(0) + 1) + (U(1) + 1) + \ldots + (U(n-1) + 1)) / n \\ &= (U(0) + U(1) + \ldots + U(n-1)) / n + 1 \end{align}\]接着,令$I(n)$表示由根节点出发到所有点的路径长度总和,因此$I(n) + n$便是这些路径上点的数量的总和,则有
\[S(n) = (I(n) + n) / n\]同样的,令$E(n)$表示由根节点出发到所有“空点”(即叶节点的左右孩子)的路径长度的总和,考虑到$n$个节点的树将有$n+1$个“空节点”,因此有
\[U(n) = E(n) / (n + 1)\]且通过数学归纳法不难证明
\[E(n) = I(n) + 2n\]总合上述等式可得,
\[\begin{align} (n + 1) U(n) &= n S(n) + n \\ S(n) &= (1 + \frac{1}{n}) U(n) - 1 \end{align}\]将$S(n) = (U(0) + U(1) + \ldots + U(n-1)) / n + 1$代入,则有
\[(n + 1)U(n) = U(0) + U(1) + \ldots + U(n - 1) + 2n\]通过错位相减的技巧,我们能够得到
\[U(n) = U(n - 1) + (\frac{2}{n + 1})\]再来一个累加求和,就有了最终结果
\[\begin{align} U(n) &= 1 + 2(\frac{1}{3} + \frac{1}{4} + \ldots + \frac{1}{n+1}) \\ &= 2(H_{n+1} - 1) \end{align}\]其中$H_n$便是我们常提到的调和级数,这也说明了为什么二叉查找树的查询在平均情况下的时间复杂度为$\mathcal{O}(\log n)$。 当然,如果只是想证明查询的复杂度的话,结合算数・递推式与生成函数中对于快速排序的平均复杂度分析,想必生成函数在此也是能够派上用场的。 同时,我们也就知道了树$T$的叶子节点到根的路径平均长度,而孤立森林正是基于此来对每一个样本数据进行打分,我们进行多次随机试验,构建若干棵不同的树,对于某个样本$x$来说,其分值$s(x, n)$为
\[s(x, n) = 2^{- \frac{E(L(x))}{2H_{n-1} - 2(n-1)/n}}\]其中$L(x)$为样本$x$在某棵树中到根的路径长度,而我们于多次随机试验中求其均值$E(L(x))$。 该分值的绝对值越接近于1,越说明其有可能是异常点。
4.后记
实际上两个算法的背后原理都是非常简单的,更多的时候难点在于根据实际情况合理的选择适用模型。 不少地方(例如scikit-learn)的文档中就有提及一类支持向量机对于异常数据相当敏感,并不适合做异常检测,更适合应用于奇异点检测(Novelty Detection),而关于模型选择的学习,想必还有相当长的路要走。